
超节点SuperPodAI算力革命的战略支点!
近年来,随着AI大模型参数规模呈指数级增长,算力需求已突破传统计算架构的承载极限。在此背景下,超节点(SuperPod)作为新型算力基础设施应运而生,成为支撑智能计算发展的关键技术路径。

业界权威机构与专家普遍认为,该技术将引领智能计算领域的重要发展趋势,并有望引发新一轮技术革新浪潮。那么,超节点的核心定义与技术价值何在?其诞生的必要性又体现在哪些方面?
超节点(SuperPod)作为英伟达提出的创新性架构概念,其本质是对传统计算节点架构的突破性重构。
在AI算力基础设施领域,GPU作为支撑AIGC大模型训练与推理的核心硬件,其集群规模需求伴随模型参数量级跃升呈现指数级增长态势。当前主流需求已从千卡级扩展至万卡级,未来或将突破十万卡量级。面对这种规模化挑战,业界主要采取两种技术路径:纵向扩展(Scale Up)与横向扩展(Scale Out)。
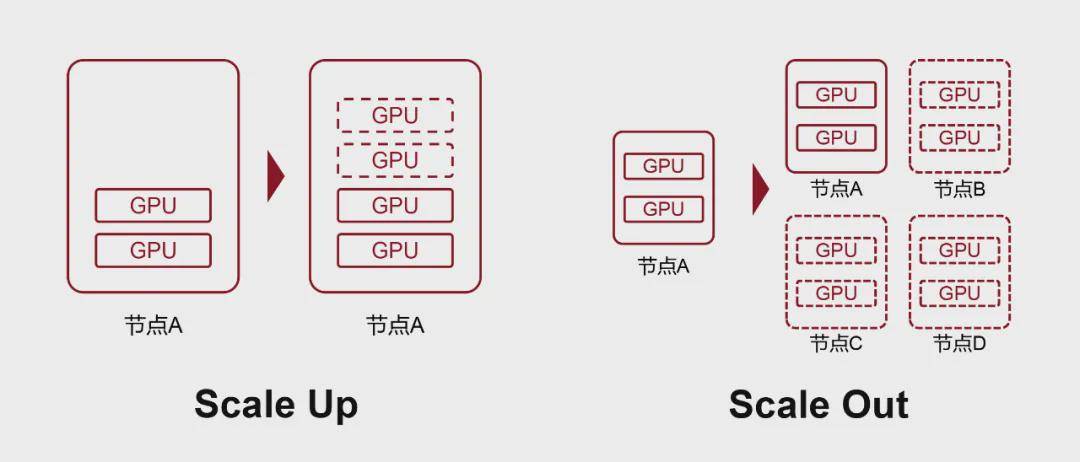
纵向扩展聚焦于单节点算力密度的提升,通过增加GPU配置数量实现算力扩容;横向扩展则通过多节点互联构建分布式计算集群。其中,单台配置8-12块GPU的服务器即构成基础计算节点。
就纵向扩展而言,传统服务器架构受限于物理空间、散热系统与功耗设计,其GPU集成上限普遍在12卡以内。更关键的是,硬件间的互联带宽与通信效率直接影响算力聚合效果。

2022年,英伟达通过独立部署NVLink交换机,将互连范围从单机扩展至多机系统,形成高带宽域(HBD)架构。这种支持16卡以上GPU集群、具备超万卡级互连带宽的纵向扩展系统,即构成超节点的核心形态。

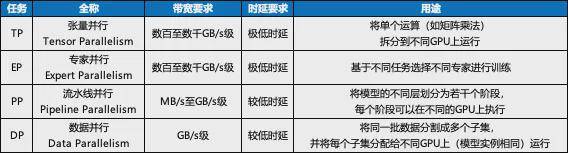
现有Infiniband与RoCEv2网络虽能提供Tbps级带宽,但其微秒级时延难以满足张量并行(TP)等高密度通信需求。超节点通过板级互连实现10Tbps级带宽与百纳秒时延,使跨GPU内存直读成为可能。
每个超节点单元相当于预集成的计算模组,大幅减少分布式系统中的节点数量。测试数据显示,256卡超节点相较8卡节点可降低38%训练成本,提升40%推理效率。

预集成架构不仅缩短50%部署周期,更通过标准化设计简化日常维护流程。模块化扩展能力支持从8卡到512卡的弹性配置,满足差异化场景需求。
以384张昇腾算力卡组成一个超节点,在目前已商用的超节点中单体规模最大,可提供高达300 PFLOPs的密集BF16算力,接近达到英伟达GB200 NVL72系统的两倍。

私有协议往往意味着高昂的成本。对于AI这个热门方向来说,发展开放标准,有利于降低行业门槛,帮助实现技术平权。目前来看,超节点的开放标准还不止一个,但基本上都是以以太网技术(ETH)为基础。因为以太网技术最成熟、最开放,也拥有最多的参与企业。
在超节点开放标准中,其中比较有代表性的,是由开放数据中心委员会(ODCC)主导、中国信通院与腾讯牵头设计的ETH-X开放超节点项目。ETH-X基于以太网技术构建大带宽、弹性可扩展的HBD,具备高算力密度、高互联带宽、高功率密度和高能效等特点。
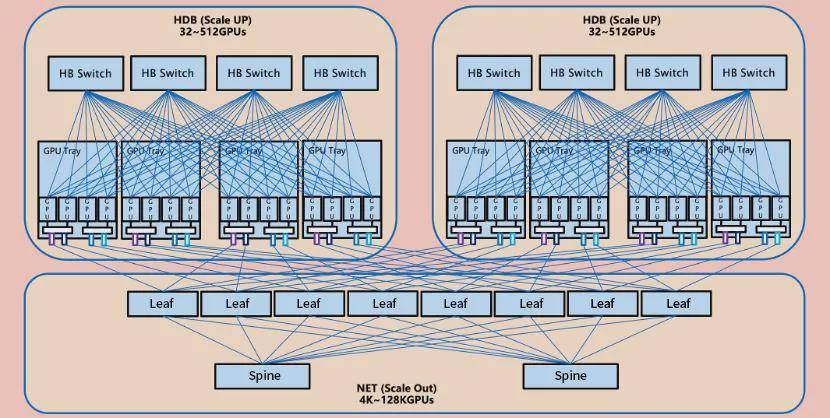
根据腾讯在开放数据中心大会提供的数据,基于ETH-X超节点,在训练场景下,LLama-70B稠密型模型在64K集群下的性能/成本进行对比,采用256卡的Scale Up,比8卡的Scale Up低了38%的训练成本。在推理场景下,LLama-70B在FP4精度128卡实例推理性能/成本对比中,256卡的Scale Up比8卡的Scale Up增加了40.48%的推理收益。
随着AI浪潮的继续发展,业界对超节点的需求会变得越来越强烈。超节点方案具有性能跃升、成本优化、架构简化三大核心优势,成为AI算力基础设施的主流选择。
其技术路线既包括英伟达、华为的私有协议方案,也涵盖ETH-X等开放标准,为不同需求场景提供灵活适配。未来,随着国产化生态的成熟和液冷等绿色技术的普及,互盟超节点将进一步推动AI算力的普惠化与可持续发展!返回搜狐,查看更多
猜你喜欢
- 05-17AICoinETH新周期下有望涨至1万美
- 05-14AICoin【提醒】9月1日起我国目录
- 05-12AICoin2024 年世界虚拟货币排行榜
- 05-15AICoin听信假军官“男友”投资
- 12-27AICoin美国监管出手虚拟币市场
- 01-11AICoin以太坊现货ETF上周净流入
- 12-20AICoinETH价格突破161天下降趋势
- 05-11AICoin揪出虚拟货币“暗网”下
- 12-20AICoin警惕虚拟货币陷阱:高回